XPath이란?
XPath은 Xml Path Language의 약자다. Selenium과 Scrapy를 사용할 경우 XPath이 큰 힘을 발휘한다.
//tagName
XPath에서는 슬래시 2개로 태그 이름을 선택할 수 있다. 예를 들어 //h1 으로 h1을 모두 선택할 수 있다.
//tagName[1]
인덱스로 선택 가능
//tagName[@AttributeName="Value"]
특정 속성 값을 가진 태그 이름을 기반으로 선택
contains()
starts-with()
//tagName[contains(@AttributeName, "Value")]
특정 값을 포함하고나 시작하는 경우 조건 추가
and
or
//tagName[(expressions 1) and (expression 2)]
ex1 그리고 ex2 모두 참인 경우 조건 추가 가능
/:
해당 캐릭터의 왼쪽에 있는 노드의 자식들을 선택하기(위계에 따른 선택). 이와 달리 //는 위계 상관없이 문서 내 어디 레벨이든 매칭되는 것이 있으면 다 가져온다.
.
현재 노드 지칭
..
부모 노드 지칭.
*
와일드카드. 현재 컨택스트에서 모든 자식 노드 선택하기
@
attribute 선택
()
XPath 표현식 그루핑
[n]
인덱스 n의 노드를 선택
실습해보자.
https://scrapinghub.github.io/xpath-playground/

//h2 : h2 태그만 가져오기
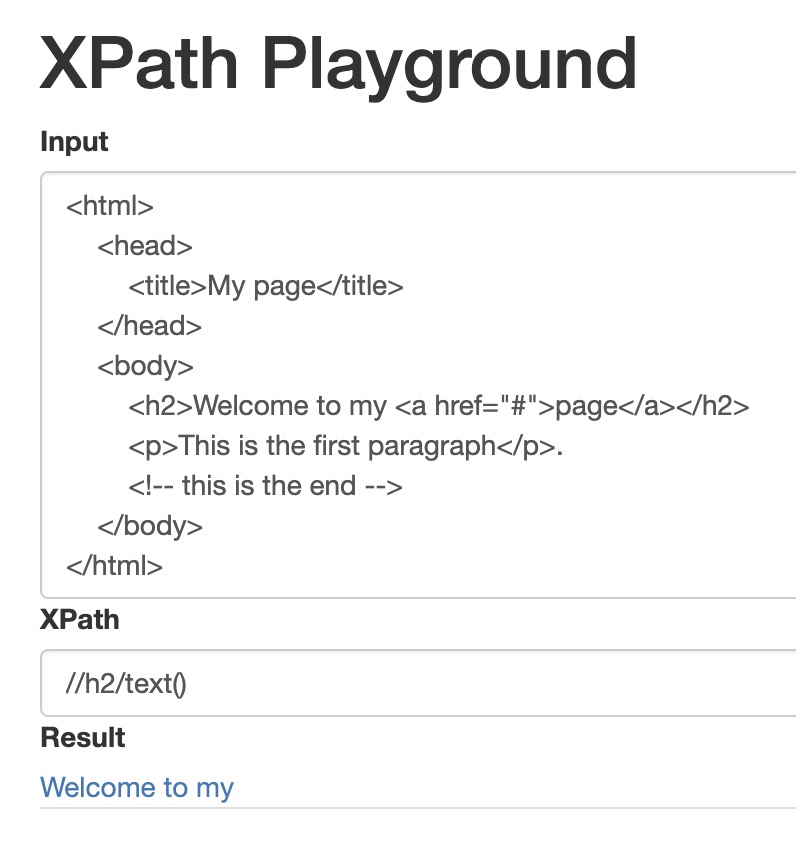
//h2/text() : h2 내 텍스트만 가져오기

p가 3개가 있는 경우다.

두번째 인덱스를 지정해서 하나만 가져오기

class라는 어트리뷰트 이름 설정하기

논리 연산자로 attribute 둘 다 선택하기

특정 문자가 포함되었는지를 contains 메소드로 확인

.. 경로로 부모노드 확인
'Research > Python' 카테고리의 다른 글
| Python_WSGI? ASGI? (0) | 2023.04.10 |
|---|---|
| Chrome_웹사이트가 자바스크립트 기반인지 확인하는 방법 (0) | 2023.03.26 |
| BeautifulSoup_여러 페이지 수집하기 (0) | 2023.03.26 |
| BeautifulSoup_Basics (0) | 2023.03.25 |
| Python_웹 스크래핑을 위한 기본 문법 (0) | 2023.03.25 |



댓글