728x90
bs4로 지니뮤직 스크래핑하여 mongoDB에 저장하기
스크래핑 타겟 : https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701
스크래핑 하기
MongoClient에 들어갈 <id>와 <pw>에는 각자 mongoDB의 아이디와 비밀번호를 넣어주면 된다.
| import requests from bs4 import BeautifulSoup from pymongo import MongoClient client = MongoClient('mongodb+srv://<id>:<pw>@cluster0.5hnlvb6.mongodb.net/?retryWrites=true&w=majority') db = client.dbsparta target = 'https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701' headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get(target, headers=headers) soup = BeautifulSoup(data.text, 'html.parser') songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr.list') for song in songs: rank = song.select_one('td.number').text[0:2].strip() # delete '19금' sign title = song.select_one('td.info > a.title.ellipsis').text.replace('19금', '').strip() artist = song.select_one('td.info > a.artist.ellipsis').text print(rank, ':', title, '/', artist) |

mongoDB에 저장하기
| import requests from bs4 import BeautifulSoup from pymongo import MongoClient client = MongoClient('mongodb+srv://<id>:<pw>@cluster0.5hnlvb6.mongodb.net/?retryWrites=true&w=majority') db = client.dbsparta target = 'https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701' headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get(target, headers=headers) soup = BeautifulSoup(data.text, 'html.parser') songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr.list') for song in songs: rank = song.select_one('td.number').text[0:2].strip() # delete '19금' sign title = song.select_one('td.info > a.title.ellipsis').text.replace('19금', '').strip() artist = song.select_one('td.info > a.artist.ellipsis').text # create dict format to insert in mongoDB doc = { 'rank': rank, 'title': title, 'artist': artist } db.musicArchive.insert_one(doc) |
결과
몽고 db에 잘 저장된 것을 알 수 있다

Trouble Shoot
bs4 스크래핑 결과 반복문 출력 시 select와 select_one의 차이
| import requests from bs4 import BeautifulSoup from pymongo import MongoClient client = MongoClient('mongodb+srv://thursdaycurryboy:thursdaylove@cluster0.5hnlvb6.mongodb.net/?retryWrites=true&w=majority') db = client.dbsparta target = 'https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701' headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get(target, headers=headers) soup = BeautifulSoup(data.text, 'html.parser') songs = soup.select('#body-content > div.newest-list > div > table > tbody > tr.list') for song in songs: rank = song.select('td.number') print('----------------------') print(rank) |
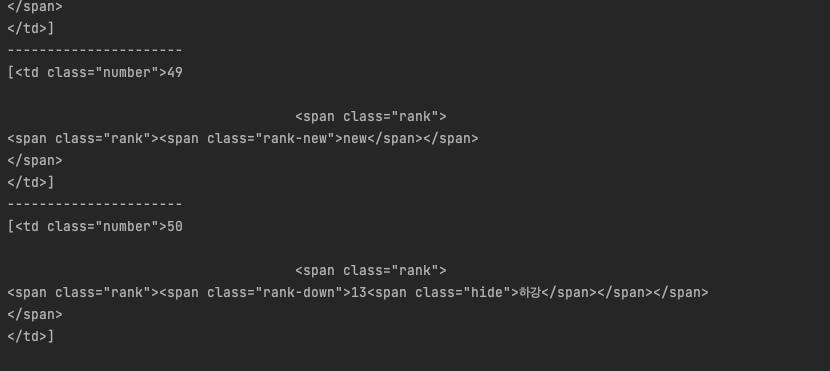
위 코드를 실행하면 위와 같이 나오는데 이를 .text화하여 본문 텍스트를 출력하려고 하는데 자꾸 에러가 나왔다.
알고보니 내가 반복문에서 rank를 select_one이 아니라 select로 모든 요소들을 찾으려고 해서 문제가 된 것 같다. select_one으로 코드를 수정해주니 정상적으로 데이터가 출력이 된다.
| ... for song in songs: rank = song.select_one('td.number').text print('----------------------') print(rank) |
위와 같이 해주니 잘 출력된다.

728x90
'World > Python' 카테고리의 다른 글
| BeautifulSoup_Basics (0) | 2023.03.25 |
|---|---|
| Python_웹 스크래핑을 위한 기본 문법 (0) | 2023.03.25 |
| bs4 select() method cheat sheet (0) | 2022.11.21 |
| bs4_파이썬으로 네이버 영화 정보 스크래핑 (0) | 2022.11.21 |
| 파이썬 gspread 라이브러리로 구글시트 다루기 (0) | 2022.02.22 |


댓글