자료 출처 : 일잘러의 비밀, 구글 스프레드 시트, 강남석 지음
6.1 IMPORTRANGE로 외부 스프레드 참조
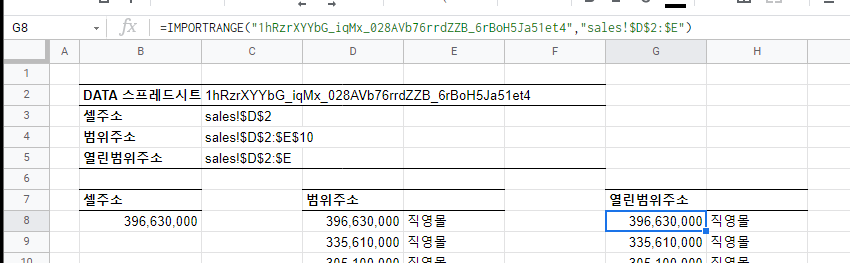
엑셀 대비 구글 시트가 가진 차별점은 외부 데이터를 IMPORT 할 수 있다는 점이다.
구글 시트의 IMPORTRANGE 장점은 아래와 같다.
- 클라우드 저장되기 때문에 시트의 물리적 위치는 상관없음
- 버전 관리하기가 용이
- 참조값 업데이트 하기 위해 참조파일 열지 않아도 됨
IMPORTRANGE
IMPORTRANGE 함수는 배열을 반환한다. 부하가 생길 수 있기 때문에 필요한 열만 참조하는 것도 좋은 방법이다.
6.2 데이터 집계의 만능 툴 QUERY 함수
QUERY 함수는 자료관리 구문 문법인 SQL 언어를 사용하여 데이터를 다룰 수 있게 해준다. QUERY에서는 SQL의 SELECT문만 사용한다.
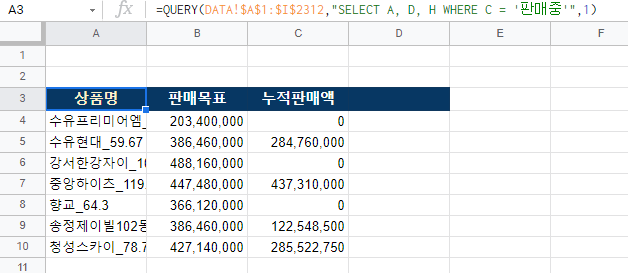
=QUERY(DATA!$A$1:$I$2312,"SELECT A, D, H WHERE C = '판매중'",1)
코드를 살펴보자. 첫 번째 인수는 DATA 범위이고 그 다음이 쿼리 구문이다. C열의 데이터가 ‘판매중’인 데이터들의 A, D, H 컬럼의 데이터를 가져오라. 그리고 마지막 1번은 HEADER 수를 말한다.
QUERY 함수 구조 에센스
=QUERY(DATA!$A$1:$I, “SELECT A, D, H WHERE C = ‘판매중’”, 1)
=QUERY(데이터 , 쿼리 , 헤더)
데이터에는 범위 배열 대부분이 올 수 있다.
- DATA!$A$1:SI
- IMPORTRANGE(...)
- FILTER(...)
- {...}
- QUERY(...)
쿼리
- SELECT 절 : SUM, AVG, COUNT, MAX, MIN, YEAR, MONTH, DAY …
- WHERE 절 : 비교연산자(<=, <, >, >=, =, !=, <>, IS NULL, IS NOT NULL, 논리 연산자(AND, OR, NOT), 문자열 비교 연산자(CONTAINS, STARTS WITH, ENDS WITH, MATCHES, LIKE)
- 문자열 형식(Literals) : 문자열, 숫자, 불리언, 날짜, 시간, 날짜/시간 등
위 내용은 잘 참고하자.
SELECT 절
SELECT절은 열 ID를 우선으로 필요로 한다. 만약 모든 열을 포함하고 싶으면 *을 표시하면 된다.
ex : SELECT *
연산자
+, -, *, /, %
집계 함수
SUM(A, B), COUNT(A)와 같이 사용할 수 있다. GROYP BY 절과 함께 사용할 수도 있다. SELECT 절 외에도 ORDER BY, LABEL, FORMAT 절에서 사용할 수 있다. WHERE, GROUP BY, PIVOT, LIMIT, OFFSET, OPTIONS 절에는 사용할 수 없다.
- AVG(), COUNT(), MAX(), MIN(), SUM()
스칼라 반환 함수
날짜값을 연도 등으로 바꿔주는 함수다.
- YEAR()
- MONTH()
- DAY()
- HOUR()
- MINUTE()
- SECOND()
- MILLISECOND()
- QUARTER()
- DAYOFWEEK()
- NOW()
- DATEDIFF()
- TODATE()
- UPPER()
- LOWER()
WHERE 절
비교 연산자
- <=, <, >, >=, =, !=, <>, IS NULL, IS NOT NULL
문자열 비교 연산자
- CONTAINS, STARTS WITH, ENDS WITH, MATCHES, LIKE
문자열 형식
- STRING
- NUMBER
- BOOLEAN
- DATE
- TIMEOFDAY
- DATETIME
GROUP BY 절
집계 함수에 집계 기준을 지정해주는 구문이다. 특정 열에 대해 집계 함수 사용 시 나머지 열에 대해서는 GROUP BY 구문을 적용해야 한다.
PIVOT 절
쿼리로 피벗 기능을 이용할 수도 있다. 집계 함수와 마찬가지로 피벗 대상이 되지 않은 열 중 집계 대상이 되는 열은 집계 함수로 처리하고 나머지 열들은 GROUP BY로 묶어 준다.
- ex) SELECT I, SUM(D), GROUP BY I, PIVOT B, C
ORDER BY 절
특정 열 순서대로 데이터 정렬하기 위해 사용.
LIMIT 절
결과값 개수 제한하기 위해 사용
- ex) SELECT * LIMIT 5
OFFSET 절
QUERY 결과에서 지정한 수만큼 행 건너뜀
- ex) SELECT * OFFSET 1
LABEL 절
특정 열 레이블 변경 시 사용함
- ex) SELECT A, B LABEL ‘Name’, B ‘Area’
FORMAT 절
특정 열의 형식을 지정한다.
- ex) SELECT * FORMAT E ‘YY/MM/DD’
QUERY 함수의 헤더 인수
헤더를 함께 출력 여부.
QUERY로 데이터 집계하기
QUERY 구문으로 요렇게 활용할 수 있다.
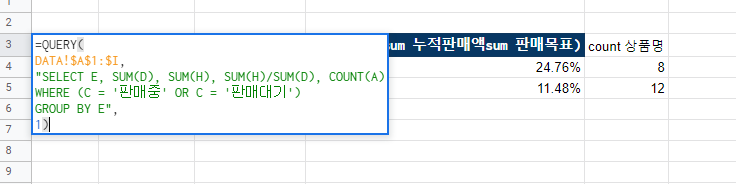

여러 부서 데이터 결합, 가공하여 QUERY 적용하기
이 내용은 현업에서 유용하게 사용할 것으로 판단된다.
예를 들어 직영몰 담당자, 오픈마켓 담당자가 별도의 스프레드 시트로 매출액을 관리하고 있다고 가정해보자. 두 시트에 있는 데이터를 모아 매출 상위 5개 상품을 판매목표, 누적판매액, 판매채널 정보와 함께 보려 한다. 작업 순서는 아래와 같다.
- 분리된 두 데이터를 한 곳에 모으고
- 모든 데이터 중 핵심 데이터만 추출
- QUERY 함수로 매출 상위 정보 집계하기
중괄호로 외부 데이터 결합
엑셀에서는 복붙 반복 작업을 해야하는 것을, 구글 시트에서는 중괄호와 IMPORTRANGE로 데이터를 한 번에 합칠 수 있다.

={IMPORTRANGE("https://docs.google.com/spreadsheets/d/1TnDB4BIgqWXfvUMPddznnmzpw_FBIOM_nl0th48UGnI/edit#gid=1395714553","직영!$A$1:$I");IMPORTRANGE("https://docs.google.com/spreadsheets/d/1jPHgjtxlNDLr9k-yLoiM646qqfl29BORFOLcXi8bvIc/edit#gid=1001236699","오픈!$A$1:$I")}
두 개의 시트의 데이터를IMPORTRAGE로 가져왔고, 이를 ‘;’로 연결해주었다. 이전에 한번 다루었는데, 중괄호를 이어붙일 때 세미콜론‘;’과 ‘,’콤마를 쓸 수 있다. 세미 콜론은 같은 컬럼의 유형을 가진 데이터들을 이어붙일 때 사용한다. 즉, STACK을 쌓는 의미로 보면 된다. 콤마’,’는 컬럼을 이어붙일 때 사용한다. A, B 칼럼에 C 칼럼을 붙여 A, B, C 칼럼으로 만들 수 있다.
위 사례의 경우 동일한 칼럼의 데이터들을 결합하는 경우이기 때문에 세미콜론을 사용했다.
단, 빈 행열도 함께 딸려 올 수 있으니 주의해서 가져오는 것이 좋다.
외부 데이터 정리 : QUERY
두 개의 외부 시트를 각각 쿼리로 일부 컬럼만 가져올 수 있다.
={query(importrange("https://docs.google.com/spreadsheets/d/1W9Z1TBdJx8JfI1Ku5BWeHTLMQkL_n76io4903ik3Ifc/edit#gid=1395714553","직영raw!$A$1:$I"),"SELECT Col1, Col2, Col3, Col4, Col5, Col6, Col7, Col8, '직영몰' where Col1 IS NOT NULL LABEL '직영몰' ''");
query(importrange("https://docs.google.com/spreadsheets/d/1HzA6r6nEt8jalWl986y6O0WFLl3Cp4cpg95UoAk8Iuk/edit#gid=1001236699", "오픈raw!$A$1:$I"),"SELECT Col1, Col2, Col3, Col4, Col5, Col6, Col7, Col8, '오픈마켓' where Col1 IS NOT NULL LABEL '오픈마켓' '판매채널'")}
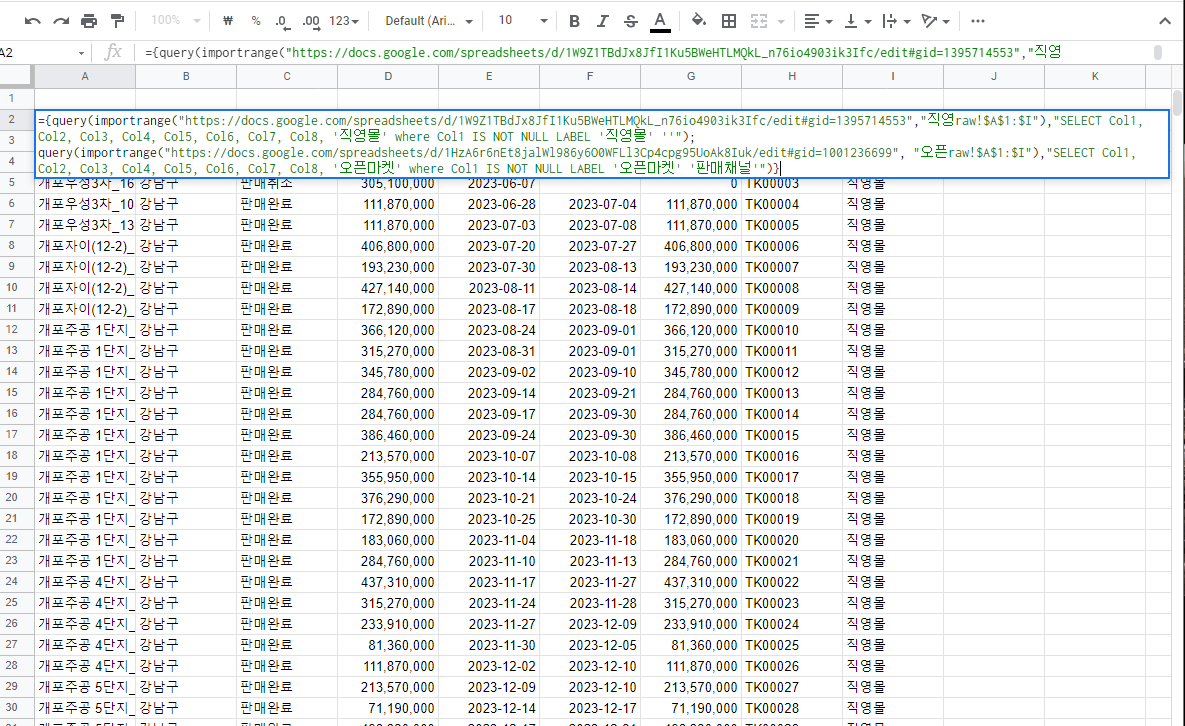
QUERY로 상위 5개 상품 끊어보기
위에서 가져온 데이터들을 범위로 잡고 다시 그중에서 특정 데이터만 가져올 수 있다. 즉, 위 데이터를 query의 range로 잡고 그중 조건에 해당하는 데이터만 가져와보자.

=query({query(importrange("https://docs.google.com/spreadsheets/d/1W9Z1TBdJx8JfI1Ku5BWeHTLMQkL_n76io4903ik3Ifc/edit#gid=1395714553","직영raw!$A$1:$I"),"SELECT Col1, Col2, Col3, Col4, Col5, Col6, Col7, Col8, '직영몰' where Col1 IS NOT NULL LABEL '직영몰' ''");
query(importrange("https://docs.google.com/spreadsheets/d/1HzA6r6nEt8jalWl986y6O0WFLl3Cp4cpg95UoAk8Iuk/edit#gid=1001236699", "오픈raw!$A$1:$I"),"SELECT Col1, Col2, Col3, Col4, Col5, Col6, Col7, Col8, '오픈마켓' where Col1 IS NOT NULL LABEL '오픈마켓' '판매채널'")},"SELECT Col1, Col8, Col9, Col4, Col7 WHERE Col3 = '판매중' ORDER BY Col7 DESC LIMIT 5")
두 시트의 데이터를 조건문으로 가져온 2개의 쿼리문들을 결합한 뒤, 이를 다시 조건문으로 쪼개주었다. 누적 판매액 TOP 5만 가져왔다.
QUERY로 피벗 테이블 만들기
아래와 같이 나타난다. 이를 피벗 테이블 옵션을 적용하면..
=query(DATA!$A$1:$J,"SELECT YEAR(F), B, SUM(H) WHERE C = '판매중' OR C='판매완료' GROUP BY YEAR(F), B ",1)

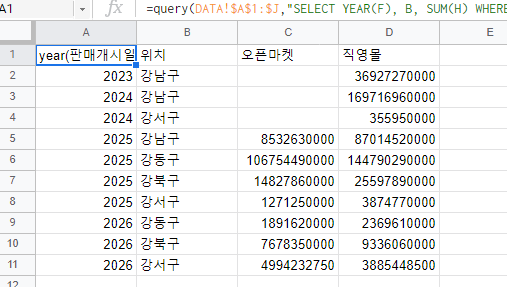
=query(DATA!$A$1:$J,"SELECT YEAR(F), B, SUM(H) WHERE C = '판매중' OR C='판매완료' GROUP BY YEAR(F), B PIVOT E",1)
이렇게 SUM 합계가 오픈마켓-직영몰로 구분된다.
숫자 포맷을 바꿔주었다.
=query(DATA!$A$1:$J,"SELECT YEAR(F), B, SUM(H) WHERE C = '판매중' OR C='판매완료' GROUP BY YEAR(F), B PIVOT E FORMAT SUM(H) '#,##0,,'",1)
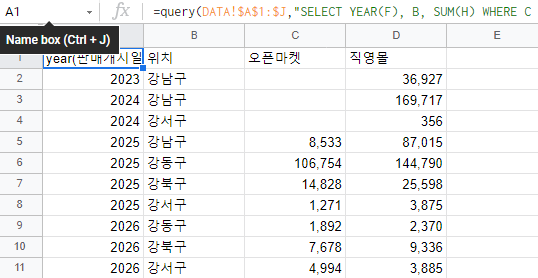
여기서 더 응용해서 DATE 기준을 추가해보자.


=query(DATA!$A$1:$J,"SELECT YEAR(F), B, SUM(H) WHERE (C = '판매중' OR C='판매완료') AND F > DATE '"&TEXT($H$1, "YYYY-MM-DD")&"' GROUP BY YEAR(F), B PIVOT E FORMAT SUM(H) '#,##0,,'",1)
$H$1 셀의 텍스트를 연도 데이터로 바꾼 뒤 이를 데이터로서 F보다 이전인 경우 조건을 추가해주었다. 멋진 피벗 기능을 코드 한줄(?)로 구현했다. 이건 거의 시트 계의 혁명이라 할 수 있다.
'World > Google products' 카테고리의 다른 글
| Googlesheet_데이터 분석하기 (0) | 2022.01.25 |
|---|---|
| Googlesheet_크롤링한 데이터 구글시트에 가져오기 (0) | 2022.01.25 |
| Googlesheet_순환 함수(ARRAYFORMULA) (0) | 2022.01.20 |
| Googlesheet_배열 다루기 (0) | 2022.01.20 |
| Googlesheet_배열 함수 사용하기 (0) | 2022.01.17 |




댓글